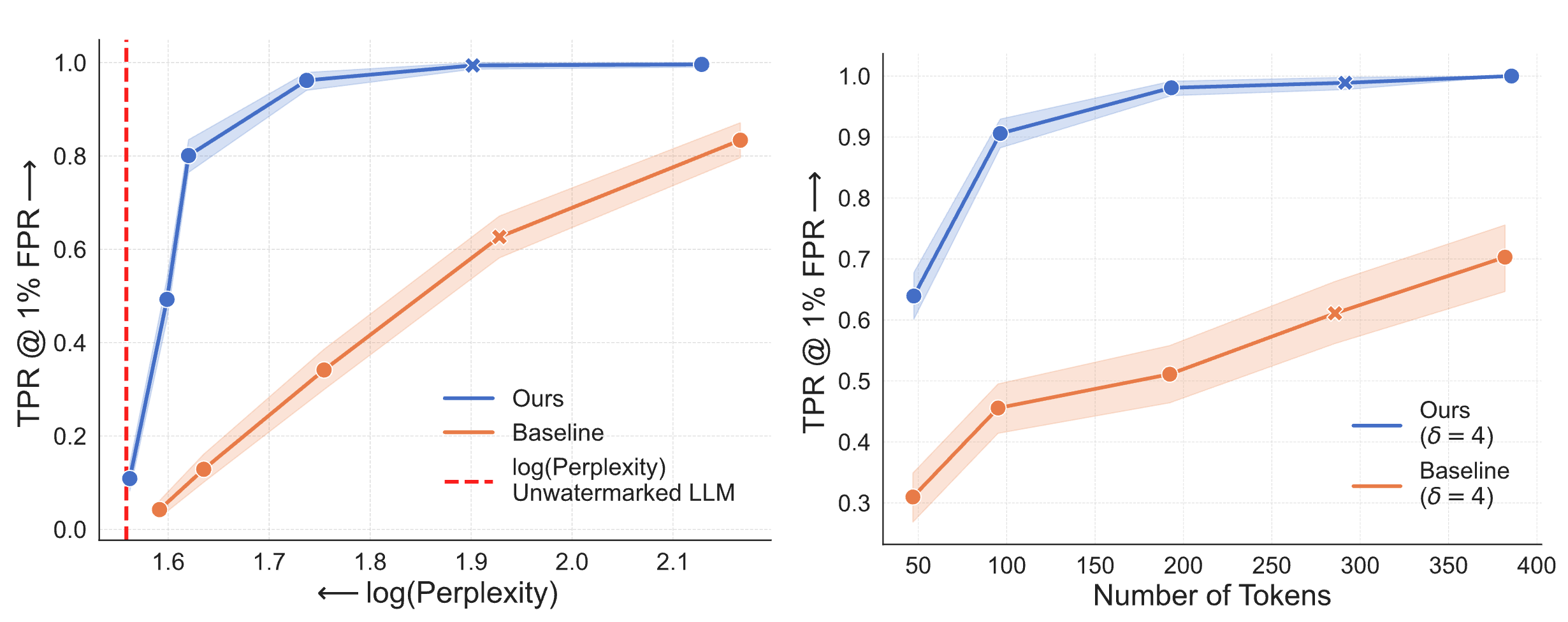
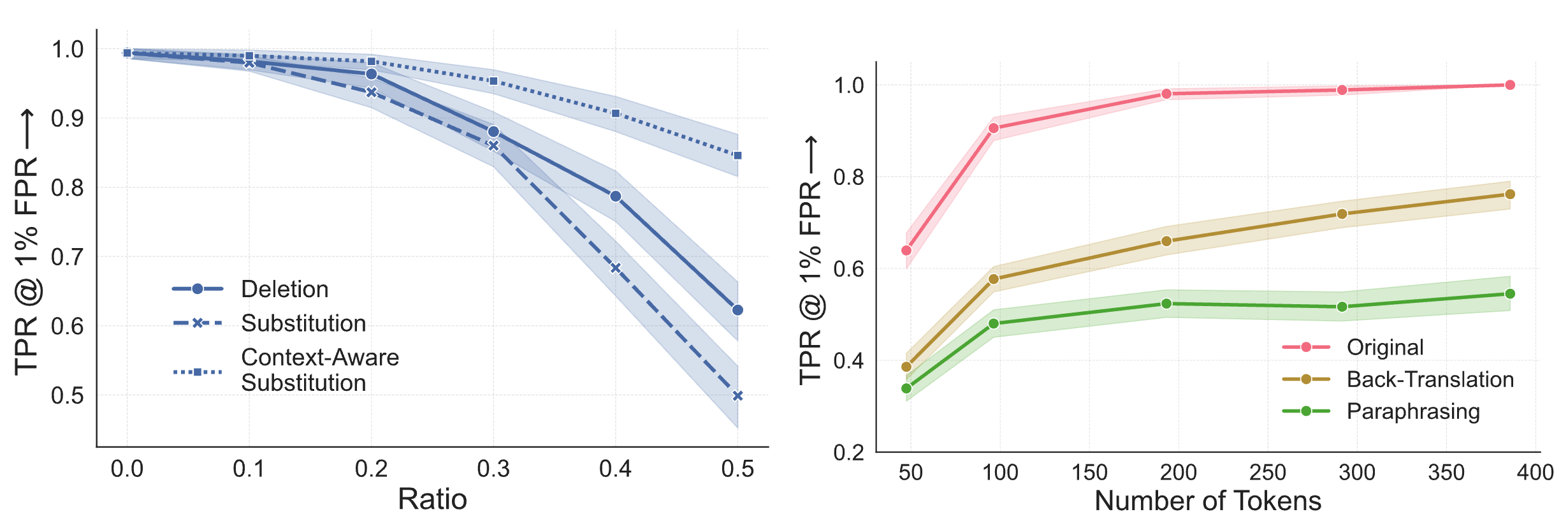
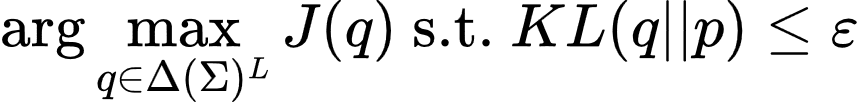Why is watermarking Diffusion LMs challenging?

With traditional autoregressive language models (ARLMs), most watermarking schemes rely on previously generated tokens (i.e., the context) to decide how to watermark the next token. For instance, Red-Green watermarks (illustrated here) hash the context to partition the vocabulary into a green and a red set. Then, the model is biased to sample tokens from the green set. For detection, the watermark detector counts the number of green tokens in a given text, and if this number is significantly higher than random chance, the text is declared watermarked.

Diffusion Language Models (DLMs) generate tokens in arbitrary order by iteratively unmasking a sequence of masked tokens (i.e., tokens yet to be generated). Importantly, this means that when generating a given token, other tokens in its context may not yet have been generated. Hence, the watermarking scheme cannot compute the hash of the context to determine the green and red sets. Thus, when generating such tokens, we cannot bias the distribution toward the green set, which weakens the watermark. This means that we need to design a new watermark that can handle masked tokens in the context.